
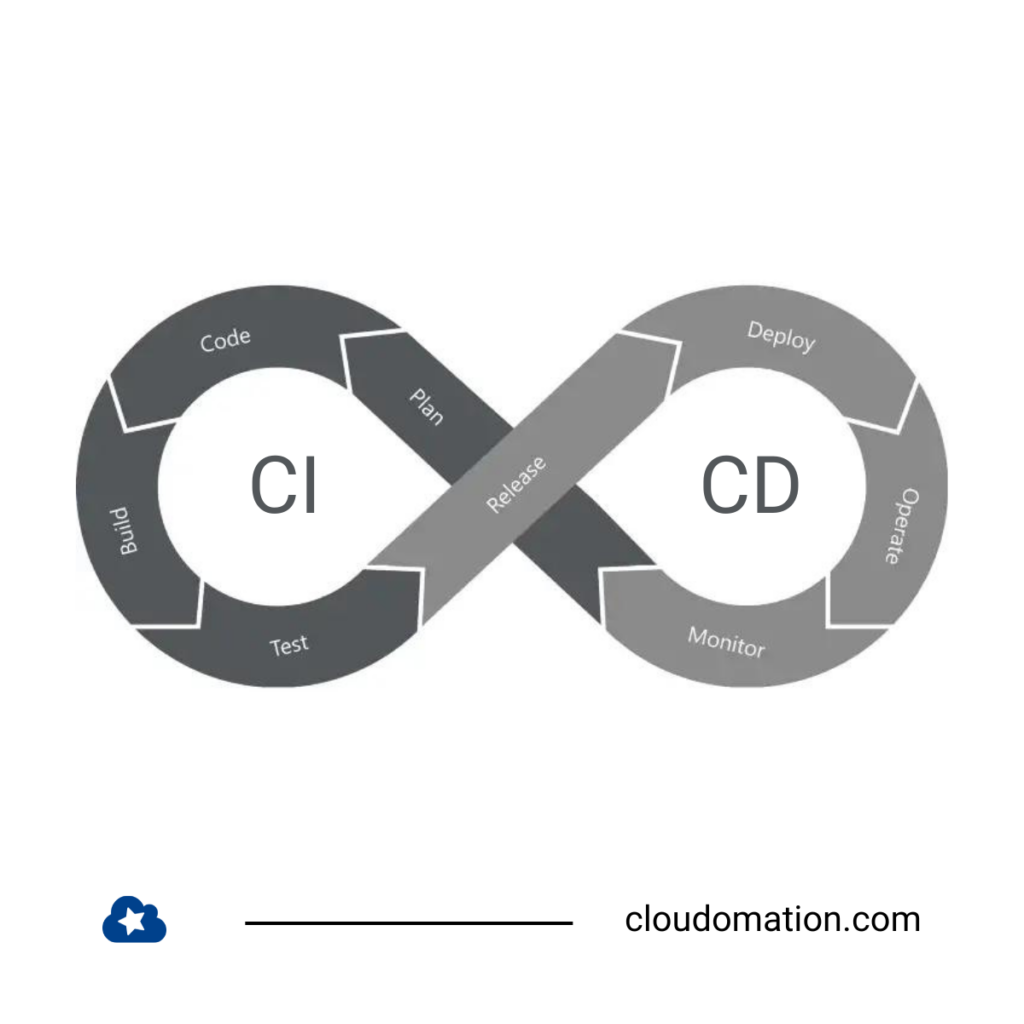
Unsere CI/CD-Pipeline
Vorab: Es gibt verschiedene Tools für die Erstellung einer CI/CD-Pipeline. Ein oft genutztes Tool ist Jenkins. Unsere CI/CD-Pipeline ist mit unserem Produkt Cloudomation umgesetzt. Die genauen Unterschieden zwischen Cloudomation und Jenkins können Sie auf unserer Vergleichsseite nachlesen.
Aufbau der CI/CD-Pipeline
Im wesentlichen besteht die Cloudomation Pipeline aus folgenden Schritten:
- Push empfangen
- Push verarbeiten
- Build-Auftrag verarbeiten
- Deploy-Auftrag verarbeiten
- Integrations-Aufträge verarbeiten

#1 Push empfangen
In diesem Schritt wird die Pipeline über einen Webhook-Call von Gitlab gestartet. Das heißt, hier wird gespeichert, dass der Push empfangen wurde und dass er verarbeitet werden soll. Jedes Mal, wenn in eines unserer Repositories gepusht wird, kommt Cloudomation Engine zum Einsatz.
In diesem Push ist folgendes enthalten:
- Wer den Push gestartet hat,
- Infos über alle Commits, die in diesem Push enthalten sind.
Dann beginnt die Verarbeitung.
#2 Push verarbeiten
Dieser Schritt ist schnell beschrieben: Der Build-Auftrag wird erstellt und die Verarbeitung gestartet.
#3 Build-Auftrag verarbeiten
Bei der Verarbeitung gibt es eine Verzweigung zu spezifischen Build-Abläufen – je nach Komponenten. Die einzelnen Build-Abläufe erstellen dann den Build. Dazu sind diese Schritte auszuführen:
- Sourcen holen
- Unittests
- Kompilierung
- Paketierung
- Pakete zum Artefact Storage hochladen
- Masterdaten-Check, welche Systeme mit der momentanen Komponente / Branch automatisch aktualisiert werden sollen. Für jedes System wird dann ein Deploy-Auftrag erstellt und die Verarbeitung gestartet.
#4 Deploy-Auftrag verarbeiten
In diesem Schritt folgen Integrationstest-Aufträge und Deployments. Wenn es sich um das interne System handelt, wird ein Integrationstest-Auftrag erstellt und die Verarbeitung gestartet. Es folgt wie im vorherigen Schritt eine Verzweigung zu spezifischen Deploy-Abläufen je nach Komponente. Diese führen die eigentlichen Deployments aus. Dazu gehört beispielsweise:
- System stoppen
- Updates installieren
- System starten
- Warten bis das System wieder erreichbar ist
- User anlegen
- System konfigurieren
- Objekte importieren etc.
Ist dieser Update-Schritt erledigt, werden für das interne System wieder Integrationstest-Aufträge erstellt. Außerdem folgen Smoketests, bei einem Nightly-Build auch Systemtests, Loadtests und Infrastruktur-Tests. Dann beginnt die Verarbeitung der Integrationstest-Aufträge.
#5 Integrationstest-Aufträge verarbeiten
In diesem Schritt wird sich ins System eingeloggt und alle Integrationstests der gewählten Kategorie werden gestartet. Dann heißt es warten und die Ergebnisse zur Überprüfung sammeln.
Warum ist die Pipeline so aufgebaut?
Unsere Pipeline ist in unserem eigenen Produkt abgebildet. So haben wir über alle Schritte die vollständige Übersicht an einem zentralen Ort. Falls ein Schritt abbricht, kommen wir über einen Link direkt zu der tatsächlichen Ausführung und können debuggen. Jeder Schritt kann außerdem manuell neu gestartet werden, zum Beispiel:
- Den selben Push z. B. mit neuen Build-Scripts noch einmal builden
- Den selben Build noch einmal deployen (Produktiv- / Kundensystem)
- Noch einmal Tests starten oder weitere ausführen
Wie ist unsere Pipeline optimiert?
Drei Optimierungen möchten wir hier nennen:
Optimierung Nr. 1: Modularität
Pipelines ganz unterschiedlicher Komponenten laufen alle im selben Schema. Das heißt, es gibt nicht vier verschiedene Pipelines für vier verschiedene Komponenten. Mit einem zentralen System sind verschiedene Anforderungen abgebildet, z. B. hinsichtlich Technologie oder Programmiersprache.
Optimierung Nr. 2: Vermeidung von Side-Effects
Oft steht man als Entwickler_in vor folgendem Problem: Es gibt einen Build-Server, der schon seit Jahren eingesetzt wird. Vor Updates scheut man sich, weil die Angst besteht, dass dann Fehler auftreten. Bei Cloudomation laufen die Builds immer auf einer frischen, soeben geklonten VM. Updates werden automatisch eingespielt. So ist der Server immer am neuesten Stand.
Optimierung Nr. 3: Geschwindigkeit
Einmal am Tag wird eine ganz neue VM aufgesetzt, die dazugehörigen Tools, Libraries und Dependencies installiert, Sourcen geklont, User eingerichtet, usw. Anschließend wird die VM gestoppt und ein Snapshot erstellt. Dieser Snapshot wird dann für die Builds verwendet. Und zwar tagesaktuell, ohne Altlasten und in Sekunden deployed.





{kind=link}