
Dies ist der erste Teil einer dreiteiligen Artikelserie. In diesem Beitrag geht es um die Herausforderungen, wenn ein Teil der von Entwickler_innen benötigten Services lokal auf dem Laptop ausgeführt werden und andere auf einem Server.
Ein häufiges Problem für Entwickler_innen, die an komplexen Kubernetes-basierten Anwendungen arbeiten, besteht darin, dass die Performance der Laptops nicht ausreicht, wenn sie versuchen, alle Services lokal auszuführen.
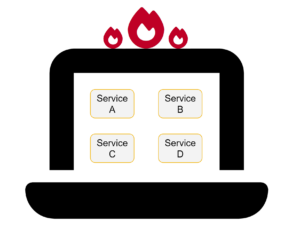
Um dem entgegenzuwirken, ist ein Setup üblich geworden, bei dem Entwickler_innen nur einen oder zwei Dienste lokal ausführen und sich mit den anderen über ein Remote-Cluster verbinden.
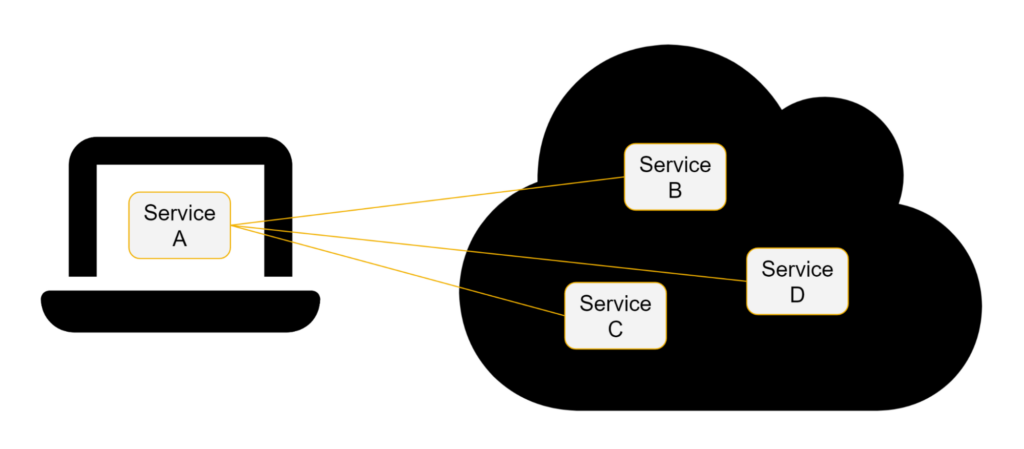
Das hat folgende Vorteile:
- Es ermöglicht die Komponenten, an denen Entwickler_innen arbeiten, lokal zu erstellen, auszuführen und zu überprüfen.
- Die Laptops werden durch die lokale Ausführung vieler Dienste nicht überlastet.
Obwohl das eine gute Idee ist, bringt dieses Setup aber einige Herausforderungen mit sich.
Herausforderung 2: Cluster-Sharing
Die Kommunikation zwischen den Diensten ist nur ein (komplizierter) Teil des (noch komplizierteren) gesamten Puzzles. Es ermöglicht einer Entwicklerin/einem Entwickler, lokale Dienste mit einem Remote-Cluster zu verbinden, auf dem die anderen Dienste laufen. Das ist gut…aber die Idee ist, einen Remote-Cluster zu haben, den alle Entwickler_innen nutzen und mit dem sie sich verbinden können. Andernfalls müsste man für jede_n Entwickler_innen einen eigenen Cluster für die Entwicklung betreiben, was teuer (und mühsam) ist.
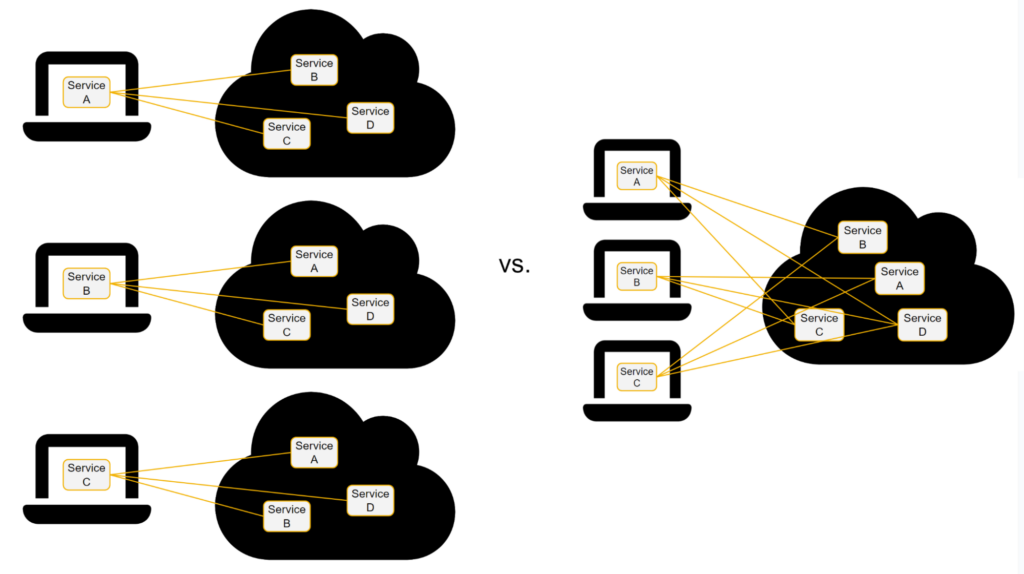
Herausforderung 2a: Multi-Tenant-Fähigkeit von Remote-Services
Wenn Sie einen Cluster für die Entwicklung haben möchten, den Entwickler_innen gemeinsam nutzen können, muss Ihre Software dies unterstützen. Konkret muss jeder einzelne Dienst mandantenfähig sein, damit mehrere andere Dienste ihn nutzen können.
Mandantenfähige Services wissen, mit welchen anderen sie kommunizieren und zu welchem Mandanten (d. h. Kunden) diese anderen Dienste gehören. Dies muss so implementiert werden, dass sichergestellt ist, dass die Dienste keine Daten zwischen den Tenants weitergeben. So muss beispielsweise eine Statistik-Komponente wissen, welche Daten zu welchem Tenant gehören, um die richtige Antwort über die richtigen Daten für den richtigen Dienst zu erzeugen.
Auch wenn es best practice ist, Microservices genau auf diese Weise zu implementieren, ist dies oft nicht der Fall. Meistens überwiegt die Komplexität des Hinzufügens einer Tenant-Trennung die wahrgenommenen unmittelbaren Vorteile, was dazu führt, dass einige oder alle Dienste nicht mandantenfähig sind.
Dienste, die nicht mandantenfähig sind, können nicht gemeinsam genutzt werden. Das bedeutet, dass Entwickler_innen eine eigene Instanz für jeden solchen nicht gemeinsam nutzbaren Dienst benötigen. Wenn nur einige Services nicht gemeinsam genutzt werden können, wäre es denkbar, einige Dienste gemeinsam zu nutzen und andere Services speziell für die Entwickler_innen bereitzustellen.

Dies ist aber mühsam zu konfigurieren, zu verwalten und bietet nur einen Teil der Kosteneinsparungen durch die gemeinsame Nutzung von Services, da viele davon immer noch in mehreren Instanzen existieren müssten.
Es lohnt sich aber, einen Punkt zu erreichen, an dem ein solches Setup ausreichend automatisiert und nutzbar ist. Denn es ermöglicht iterative Verbesserungen, bei denen die Multi-Tenant-Unterstützung schrittweise zu einzelnen Diensten hinzugefügt werden kann, wodurch Kosteneinsparungen durch die gemeinsame Nutzung von Diensten schrittweise erhöht werden.
Nebenbei bemerkt: Multi-Tenancy ist nicht nur für die gemeinsame Nutzung von Diensten in der Entwicklung von Vorteil, sondern auch für eine effiziente Skalierung in der Produktion. Der Use Case ist derselbe: Jeder Dienst, der nicht gemeinsam genutzt werden kann, existiert als dedizierter Dienst für jeden Kunden. Sie können nach oben skaliert werden (d. h. es können mehrere Instanzen dieses Dienstes für einen Kunden existieren), aber sie können nicht nach unten skaliert werden (d. h. es muss für jeden Kunden mindestens eine Instanz dieses Dienstes existieren). Dies reduziert die Vorteile einer Microservices-Architektur erheblich und erhöht gleichzeitig die Komplexität ihrer Verwaltung. Wenn nur einige Dienste gemeinsam genutzt werden können und andere nicht, muss dies bei der Skalierung berücksichtigt werden, was das Unterfangen sehr viel komplexer macht.
Herausforderung 2b: Versionierung und Verwaltung der Kompatibilität von Diensten
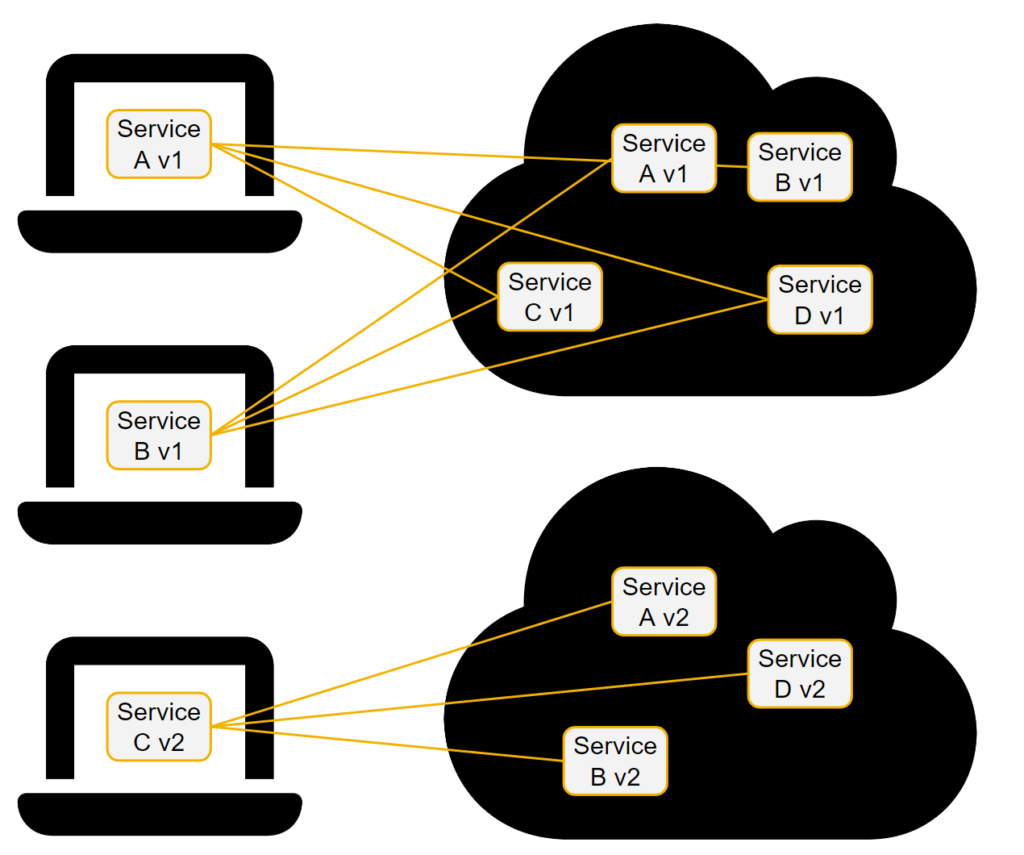
Der nächste Knackpunkt ist die Kompatibilität der Dienste. Wenn Sie verschiedene Teams haben, die an verschiedenen Komponenten arbeiten, würde die Einführung einer grundlegenden Änderung in einer der Komponenten entweder erfordern
- dass beide Versionen dieser Komponente auf dem Cluster der Entwicklung verfügbar sind, damit sich andere Dienste damit verbinden können – was Versions-Kenntnis voraussetzt, d. h. jeder Dienst muss seine eigene Version kennen und wissen, mit welchen anderen Versionen anderer Dienste er kompatibel ist. Auch das ist Best Practice, aber in der Realität sind Softwares oftmals nicht dafür ausgelegt.
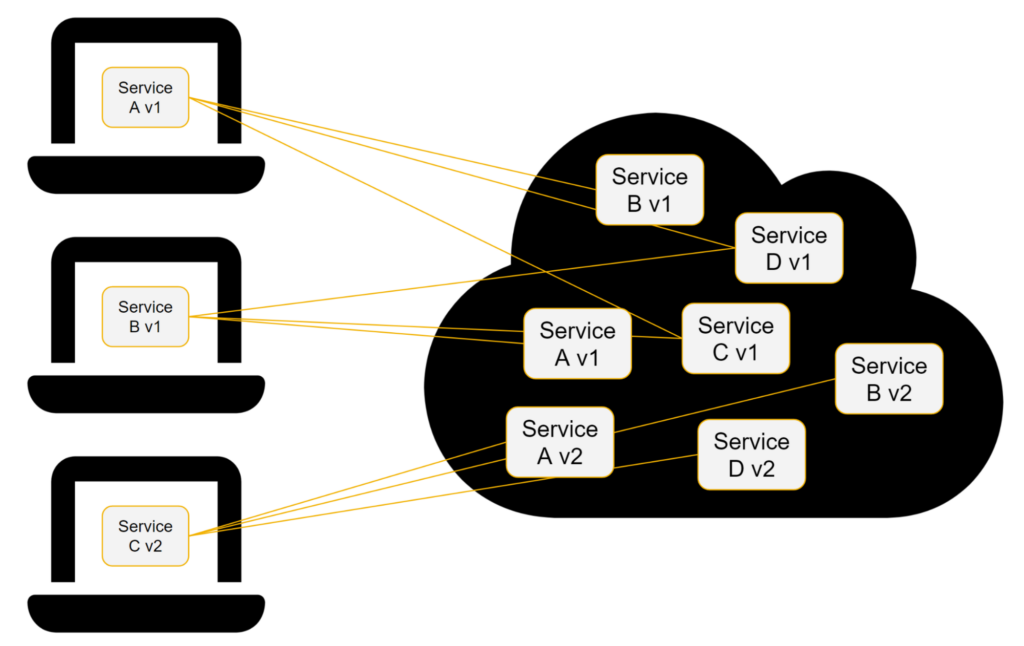
- Oder Sie benötigen separate Cluster für verschiedene Versionen, und jede_r Entwickler_in muss wissen, gegen welchen Cluster er entwickeln soll. Das ist einfacher zu verwalten, aber Sie benötigen einen zusätzlichen Cluster für jede Version, an der die Entwickler_innen arbeiten.
Eine Möglichkeit, mit Kompatibilitätsproblemen umzugehen, besteht für viele Unternehmen darin, grundlegende Änderungen um jeden Preis zu vermeiden und der Abwärtskompatibilität Vorrang vor den meisten anderen Aspekten (wie technische Exzellenz oder Benutzerfreundlichkeit) einzuräumen.
Leider ist dies oft ein Weg, Probleme in andere Bereiche zu verschieben, anstatt sie zu lösen. Die Einschränkung der Möglichkeit, wesentliche Änderungen vorzunehmen, führt zu einer Anhäufung von technischen Altlasten, die jede einzelne zusätzliche Änderung an der Software komplexer und kostspieliger macht.
Dies kann zu einer „Katze beißt sich in den Schwanz“-Situation werden: Die Abwärtskompatibilität mit älteren Versionen, die nicht über mandantenfähige Funktionen verfügen, macht es unmöglich, mandantenfähige Funktionen einzuführen, da diese grundlegende Änderungen an der Struktur und dem Inhalt von API-Anfragen erfordern.




{kind=link}